So you’ve decided you want a high availability cluster running on FreeBSD?
A common setup is to run haproxy + CARP together. The main drawback to this method that that it isn’t truly high availability. Here are some of the shortcomings of this approach:
- You will need to upgrade the haproxy binary an awful lot, if your are doing SSL termination. You will need to fail-over the carp master when preforming maintenance on the host
- What happens to existing in-flight requests?
- Do you always have a service window?
- If the haproxy process on the MASTER dies (or say isn’t accepting requests on a reload), those requests aren’t serviced
- Additionally how does CARP know the status of the haproxy process? It doesn’t.
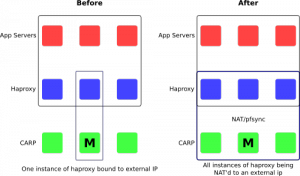
- Only one haproxy instance is serving all of the requests at a time, so you aren’t really load balancing the requests
All of this stems from the fact that we are missing a layer of redundancy. We have redundancy at the physical layer with CARP. We have redundancy at the application (or transport) layer with haproxy.
What we need is redundancy at the network layer to complete the stack.
I am told you can solve this in linux with LVS, but currently (as far as I’m aware) there is no mechanism for this in the BSD world.
Insight: Use pf + NAT!
We can use the built-in functionality of pf to allow us to add redundancy and much more versatility at the network layer:
We configure our external addresses to point to a pool of internal haproxy addresses:
rdr inet proto tcp from any to <ext-std> port { http, https } -> <int-std> source-hash
In our case, ext-std is a set of IPs that we are maintaining for one haproxy frontend, http(s) standard, in this case. This then redirects to a pool of haproxy servers internally to service the requests.
There are a few different pool options that we can use to assign incoming traffic to a particular host. In the case of tls-protected traffic, it is best to try and stick the same sessions to the same servers. Using something like source-hash, instead of round-robin is a good way to do this, although you will have side effects (loss of tls session id, and ssl renegotiation) when adding/removing entries from the int-std table. (There is some facility for sharing tls-ticket secrets in haproxy that would avoid this problem. It requires an haproxy restart, and but I haven’t quite figured out the mechanics of this in a non-service impacting way just yet).
Additionally, we need to share the NAT state using pfsync, so that in the event of a CARP master failing, the new master can seamlessly continue to route traffic (except to maybe the haproxy instance that happened to be running on the CARP master).
What you end up with is n-haproxy instances, that are simultaneously processing traffic. Each instance can independently be detached from new incoming requests via the pf tables that are used in the redirect rules. You can change the pf configuration without adversely affecting traffic.
… but what if an haproxy instance disappears?
Remember how I flagged CARP not knowing when your haproxy process disappears? There is a missing component in the stock tools. For each pf instance, we are maintaining a pf table of haproxy hosts. We need this to be the table of up haproxy hosts.
Enter hfm.
hfm is a program that I developed to solve the problem of knowing which hosts are up from the view of a pf instance. Each pf instance has its own view of the network, and needs to poll each haproxy instance. (This makes perfect sense in the case of a network partition. We need to ensure that the pf instance is only routing traffic to hosts it can actually communicate with.)
hfm can’t actually do the task at hand on its own. That’s a good thing. This means that for every conceivable service, you can write a test script that answers yea or nay. Additionally you can define a script to take any action when yea changes to nay, and a different one the other way around.
Example configuration (may not actually work!)
This is just meant to be a rough sketch to get you off to the races. I’ll nail down a real config Real Soon Now.
pf.conf:
table <haproxy-ext-std> { 192.168.9.234, 192.168.38.12 }
table <haproxy-int-std> persist
rdr inet proto tcp from any to <haproxy-ext-std> port { http, https } -> <haproxy-int-std> source-hash
rdr inet proto tcp from any to <haproxy-ext-nonstd-whatever> port { http, https } -> <haproxy-int-nonstd-whatever> source-hash
hfm.conf (FreeBSD-specific fetch, could use curl instead):
interval=1s
timeout_int=1s
timeout_kill=2s
lb1 {
haproxy {
test=”fetch”
test_arguments=[
“–no-verify-hostname”,
“–no-verify-peer”,
“–no-sslv3”,
“-o”,
“/dev/null”,
“-T1”,
“-q”,
“https://lb1-service/haproxy_check”
]
change_success=”haproxy_change”
change_success_arguments=[ “up”, “lb1” ]
change_fail=”haproxy_change”
change_fail_arguments=[ “down”, “lb1” ]
}
}
lb2 {
haproxy {
test=”fetch”
test_arguments=[
“–no-verify-hostname”,
“–no-verify-peer”,
“–no-sslv3”,
“-o”,
“/dev/null”,
“-T1”,
“-q”,
“https://lb2-service/haproxy_check”
]
change_success=”haproxy_change”
change_success_arguments=[ “up”, “lb2” ]
change_fail=”haproxy_change”
change_fail_arguments=[ “down”, “lb2” ]
}
}
haproxy_change (FreeBSD-specific, obviously pfctl):
#!/bin/sh
# this file is tightly coupled with your pf.conf
#$1 action, $2 host group
toggle_host() {
local action=”add”
if [ “$1” == “down” ]; then
action=”delete”
fi
sudo sh -c “pfctl -q -t haproxy-int-std -T $action $2-http-std; pfctl -q -t haproxy-int-nonstd-whatever -T $action $2-http-nonstd-whatever; “
}
toggle_host “$1” “$2”
haproxy.conf :
…
frontend service
# use https, because we want to fail the service if https isn’t working (it fails differently than http)
bind lb-service https crt yourcerthere.pem
monitor-uri /haproxy_check
monitor fail if { nbsrv(signal-down) lt 1 }
frontend signal-down
bind localhost 9999
server dummy localhost:38383
frontend http-std
bind http-std http
bind http-std https crt yourcerthere.pem
default_backend yourbackend here
frontend http-nonstd-whatever
bind http-nonstd-whatever http
bind http-nonstd-whatever https crt yourcerthere.pem
default_backend yourbackend here
In this particular configuration, we are polling a monitor-only frontend, that can signal whether our haproxy instance is healthy or not. From there, we need to fail, or add the groups of our IPs for all of the frontends configured in that haproxy instance as a unit.
One benefit of this configuration, is that the host serving the haproxy instance can now signal to the firewall that it is about to be reconfigured, by force-failing the monitor check ahead of the reload (you down the dummy server over netcat on the admin socket, in this example). This will stop new traffic from arriving on the reloading haproxy instance, and you will be able to process that request immediately via another instance, rather than dropping SYN packets, or introducing a delay. When the haproxy instance returns, it is automatically added back to the pool (you may need to up the dummy server again).
You can see now that it would be trivial to maintain a cluster of any other services in a similar fashion. We do something like this for our outbound proxy services as well, in the same configuration.
Why go to all that effort
You might say “why go to all that effort when you can just use X”, for X in:
relayd
Clearly this is what relayd was mean for. What gets me, and maybe I’m doing it wrong, is that at least the FreeBSD port of relayd erases the entire pf configuration, including forwarding table on a reload. So, until the new configuration is loaded, where oh where do your packets go? We need to be able to reconfigure whatever service is doing the network redundancy, in a service preserving fashion.
keepalived
Is dead in FreeBSD. It is tightly-coupled to LVS.
script-fu
It is conceivable to fill this niche with a custom (say bash) script. In fact, that was our first iteration. However, it is very hard to write something that scales. In production, you will likely have multiple services, and additionally, the checks for the service health are likely different. You need to check in parallel. Additionally, you need to ensure service level from each check (if you want to check on the interval of 1 second, but when things fail, it takes the check 5 seconds to recognise that the handshake was interrupted). This really seemed to be fighting uphill. What about {ruby, python, etc} – yes, now we need to program something, why introduce external dependencies?
?
I did research for more options, and came up empty. If you haven another tool that fits neatly in this space, I’d love to know!
source-hash doesn’t work with address tables (at least in 10.3)
@Rolandas
Thanks for the info. Is this something you’ve discovered experimentally, or is there a PR for it?
I’m working on a similar setup right now and running into the same issue. The problem is that even in current OpenBSD pf docs, CIDR is required to be able to source-hash on a rdr. You can only do round-robin to a table. You get the error “tables are only supported in round-robin redirection pools” if you try to use a table in a rdr rule.
I’m not sure how I’m going to handle it going forward. This setup will still be more flexible and robust than the commercial load balancer it’s replacing even without this piece.
I’m already a couple reverse-proxies deep and don’t want to add too many more levels if I can help it. I’m going to have to go do some more digging.
@Dale Shrauger
You can add sticky-address to round-robin and “set timeout src.track (number of seconds)” to adjust how long it retains the source address after the state expires from the pf state table.
This will take some trial and error to make sure you don’t eat up all your memory trying to hold the entries in the table too long.
@Dale Shrauger
Thanks for that feedback. The only benefit here would be the SSL fast start-up. Non-SSL should round-robin everywhere else just fine. Nothing should break either, just higher startup latency.
It would be interesting to implement consistent hashing here (with source-hash + tables).
Additionally, this BSDCan talk, he suggests using route-to, and then you also avoid state tables. Key to DDoS mitigation. Although you can’t replicate the state using pfsync. Also has an interesting idea about RST’ing downed TCP connections.
https://youtu.be/Wvlao_YhcdY
Interested to know if you run hfm for process monitoring or not, in the end?